
视频教程
哔哩哔哩:https://www.bilibili.com/video/BV14aNReMEpE/
今日头条:https://www.toutiao.com/video/7469699907520348682/
抖音:https://v.douyin.com/iPhWb8Hx/
youtube:https://youtu.be/bfwSh5eJqdc
对于我们普通人来说,deepseek的本地部署,市场上用的最多的有两个软件,分别是Lm studio和ollama,本次教程我们使用ollama,ollama的问答是在命令框里,交互不方便,所以我们还要搭配可视化的界面来使用,本教程我们使用的是chatbox。
1、安装ollama
访问ollama的官网:https://ollama.com/
下载对应的版本,提供MacOS,linux和windows的版本,windows要求在win10以上,下载好后安装,基本没啥复杂的步骤,下一步下一步即可。
2、运行ollama
先看下自己的状态栏里ollama是否运行,右键这个图标选择quit ollama可以在后台退出ollama,减少占用
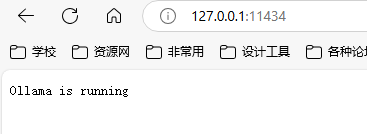
浏览器访问http://127.0.0.1:11434/,也可以验证ollama是否在运行
假如没有的话,去ollama的安装文件夹双击ollama app.exe即可启动
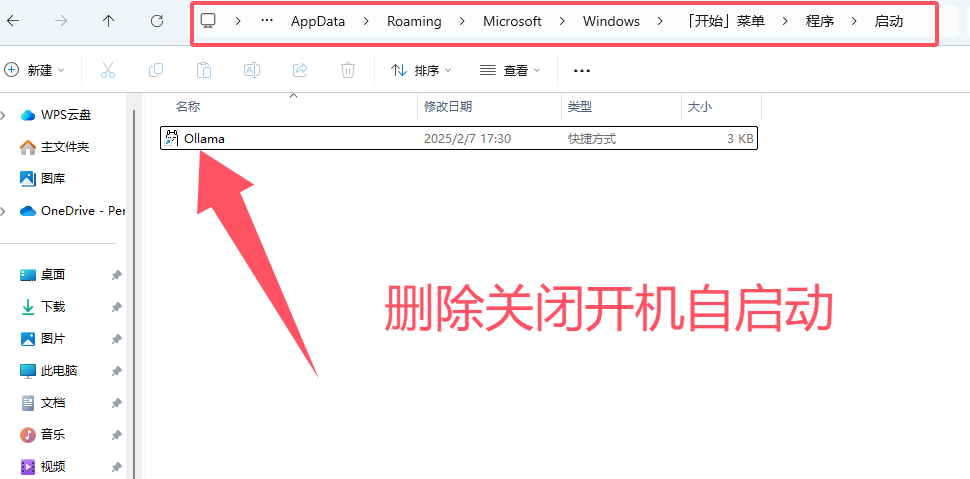
3、关闭开机自启(可选)
ollama默认是随系统启动的,为了减少占用可以关闭自启,需要用的时候手动开,文件夹地址栏访问下面的地址
%APPDATA%\Microsoft\Windows\Start Menu\Programs\Startup
删除ollama启动快捷方式即可
4、拉取deepseek模型
国内的模型网站有很多,可以选择ollama官方的模型库,点击顶部菜单的Models即可看到,目前热度排名第一的就是deepseek
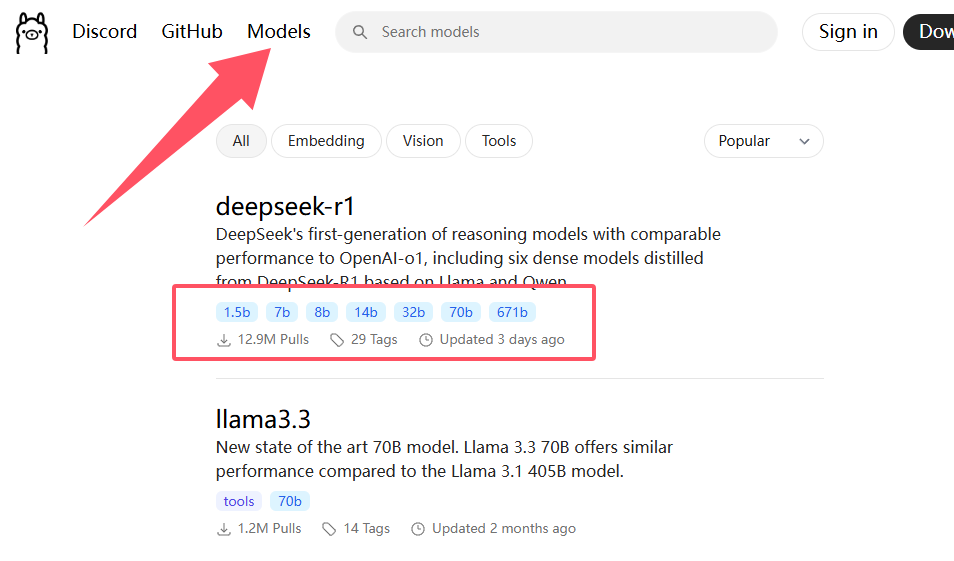
点击进入后可以看到不同参数量的模型,其中官方用了671b的参数量,这是我们个人电脑所不能企及的,建议量力选择,1.5b不需要调用独显,可以说大部分设备,甚至手机也可以完成,但效果也是最差的,网友的话就是人工智障,拥有独立显卡的都可以尝试7b或者8b,效果日常对话没啥问题,只能说差强人意。假如独显较好,拥有8g显存,那可以尝试14b,假如是顶级消费显卡,那可以尝试32b,70b土豪可以尝试。
确认运行ollama后,右键开始菜单,打开终端,或者win+r键输入cmd打开,都可以打开cmd命令行工具。
输入下面的命令
ollama run deepseek-r1:1.5b
其中1.5b可以改为你要的参数量,比如8b
ollama run deepseek-r1:8b
然后回车,ollama就会开始拉取模型
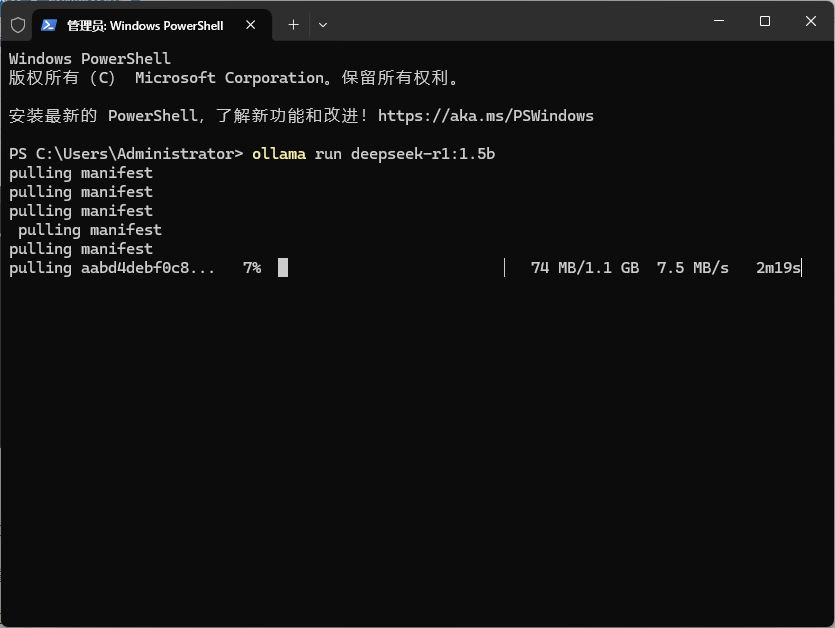
模型拉取完后,就可以直接进行对话
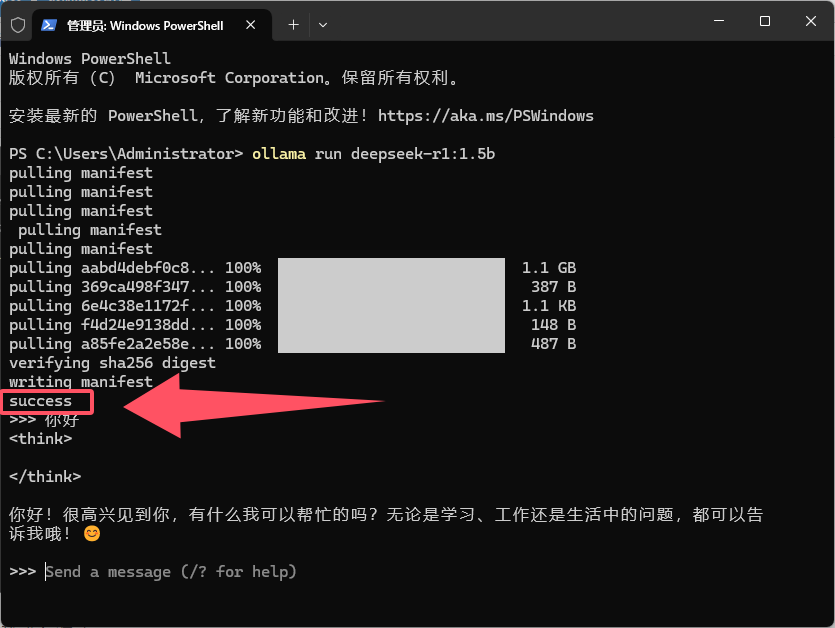
根据信息回复的时间间隔,我们可以大致判断你的硬件配置是否能带的动模型
顺便列几个常用的ollama命令:
运行模型:ollama run 模型名
查看本地所有模型:ollama list
删除指定模型:ollama rm 模型名
5、安装可视化界面chatbox
访问chatbox官网:https://chatboxai.app/zh,下载软件并安装
安装方式基本也是一直下一步
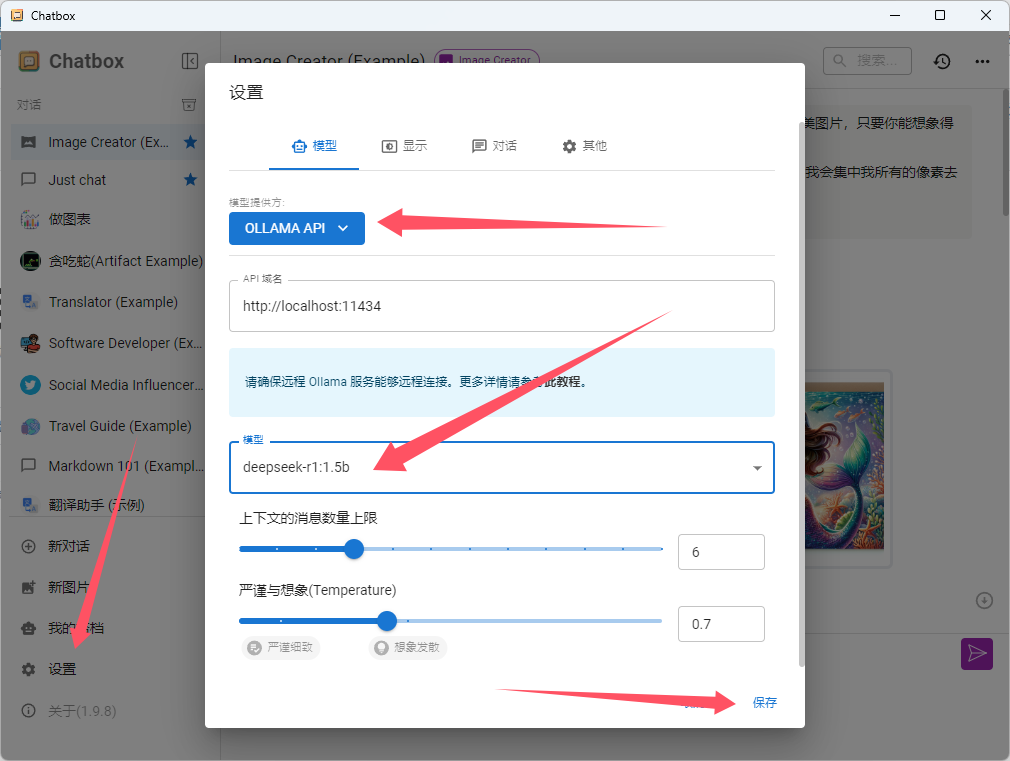
安装好后点击设置,选择ollama,选择自己安装并且正在运行的模型,保存
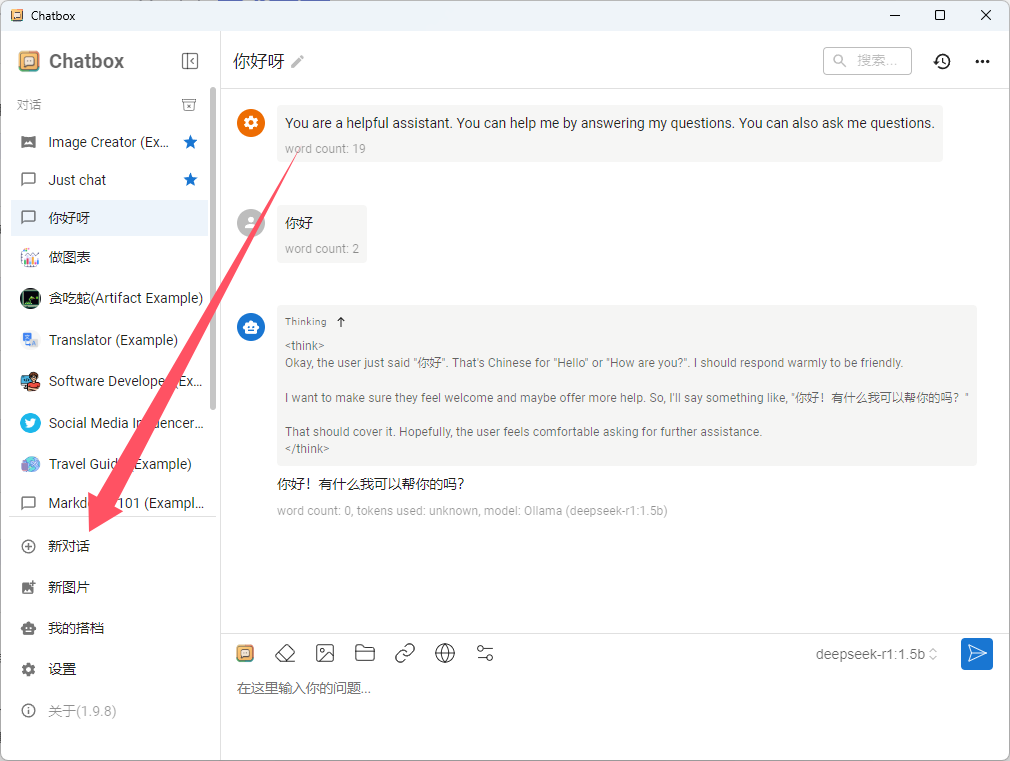
点击新对话,就可以开始愉快的聊天了
本文来自于大海资源网(dhzy.fun)原创,欢迎转载,当然要是能加个来源就更加感激不尽了!!!






